
[인사이드 머신] - 파이프라인 해저드
해저드
- 두 명령어가 동시에 병렬적으로 수행되지 못한 경우 이런 조건을 해저드라고 한다.
- 이 해저드의 발생 상황과 해결 방법에 대해 알아본다.
해저드의 종류
- 데이터 해저드
- RAW/WAW/WAR 데이터 의존성과 메모리 의존성으로 발생.
- 구조 해저드
- 하드웨어 자원 부족으로 발생.
- 제어 해저드
- 분기 조건의 있으면 분기 조건을 평가하고, 분기 목적지를 계산할 때까지 파이프라인이 멈춰 발생.
Data Hazards - 데이터 해저드
- 데이터 해저드는 RAW/WAW/WAR 데이터 의존성과 메모리 의존성으로 발생한다.
데이터 의존성의 종류
RAW ( Read After Write )
- 앞선 연산에서 Write 하는 메모리를 뒷 연산이 Read 하는 경우 발생.
- 2행에서 C 레지스터는 1행의 연산이 끝나야 값을 알 수 있다.
 Read After Write
Read After Write
- 2행에서 C 레지스터는 1행의 연산이 끝나야 값을 알 수 있다.
WAW ( Write After Write )
- 앞선 연산에서 Write 하는 메모리를 뒷 연산이 Write 하는 경우 발생.
- 1행에서 레지스터 E에 결과를 쓰고, 2행 역시 레지스터 E에 결과를 쓴다.
 Read After Write
Read After Write
- 1행에서 레지스터 E에 결과를 쓰고, 2행 역시 레지스터 E에 결과를 쓴다.
WAR ( Write After Read )
- 앞선 연산에서 Read 하는 메모리를 뒷 연산이 Write 하는 경우 발생.
- 1행에서 레지스터A 를 읽고, 2행에선 이 레지스터 A 에 쓴다.
 Read After Write
Read After Write
- 1행에서 레지스터A 를 읽고, 2행에선 이 레지스터 A 에 쓴다.
- WAW, WAR 는 Register Rename 기법으로 쉽게 처리할 수 있어
가짜 의존성 또는 거짓 레지스터 충돌이라고 부르기도 한다. - RAW 는 단순 Register Rename 과 같은 방법이 통하지 않기 때문에 진짜 의존성 이라고 부른다.
RAW 의존성의 해결 방법
데이터 해저드 RAW 예제
- 첫번째 연산 결과가 레지스터 C에 쓰기가 완료된 후에야, 두번째 add 명령어가 수행 될 수있다.
- 4단계 파이프라인에서 Fetch 단계는 각 레지스터의 값을 가져와 실제 ALU 에서 실행한다.
- 즉 1행의 결과를 쓰기전에는 레지스터 C의 값을 가져올 수 없다.
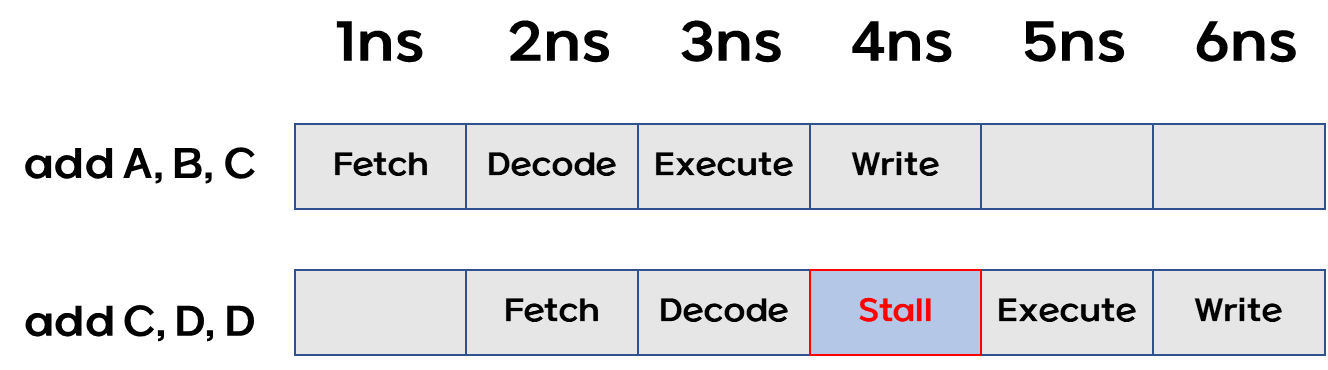 데이터 해저드 파이프라인 멈춤 발생
데이터 해저드 파이프라인 멈춤 발생
Pipeline forwarding(PF) - 포워딩 기법
- add 명령어의 결과를 레지스터 C 에 쓰는 작업을 건너뛰고,
연산 결과를 ALU 출력 포트에서 다음 명령어의 ALU 입력 포트로 바로 공급.- 이럴 경우 첫번째 명령어의 수행 스테이지를 완료하면 두번째 add 가 가능하다.
- 이는 하드웨어의 특별한 설계를 필요로 한다.
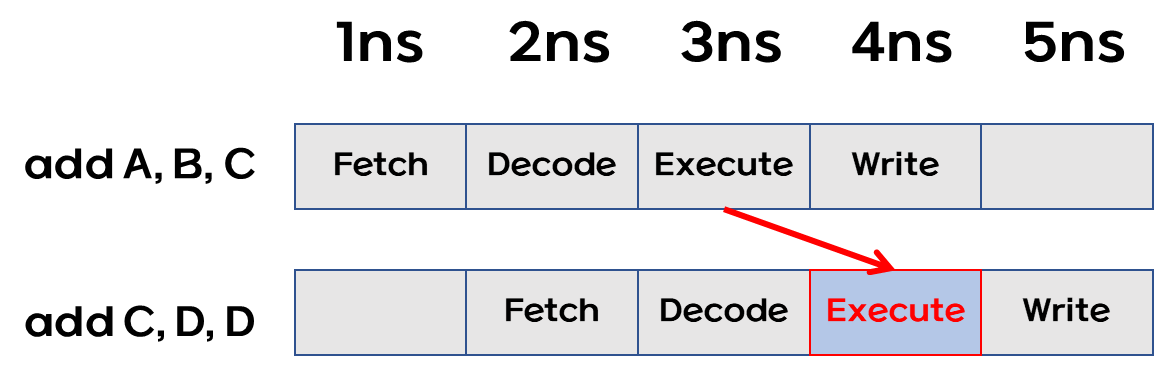 포워딩 기법의 활용
포워딩 기법의 활용
WAW, WAR 의존성의 해결 방법
- 거짓 레지스터 충돌이 나는 경우 사용 가능
Write After Read
- 아래 그림에서 IU1 레지스터와 IU2 레지스터는 실제 서로 다른 물리 레지스터를 사용하지만,
프로그래밍 모델의 범용 레지스터는 A, B, C, D 만 사용.- 위의 두 add 는 실제 의존성이 없음에도 레지스터 이름 충돌이 발생.
Register Rename - 레지스터 리네임
- 임시 레지스터를 이용하여 2 개의 add 명령어를 모두 병렬적으로 수행한 뒤,
둘째 add 의 결과를 임시 레지스터에 쓰고, 첫째 명령어가 A 레지스터를 읽은 뒤 레지스터 A 에 결과를 쓴다.
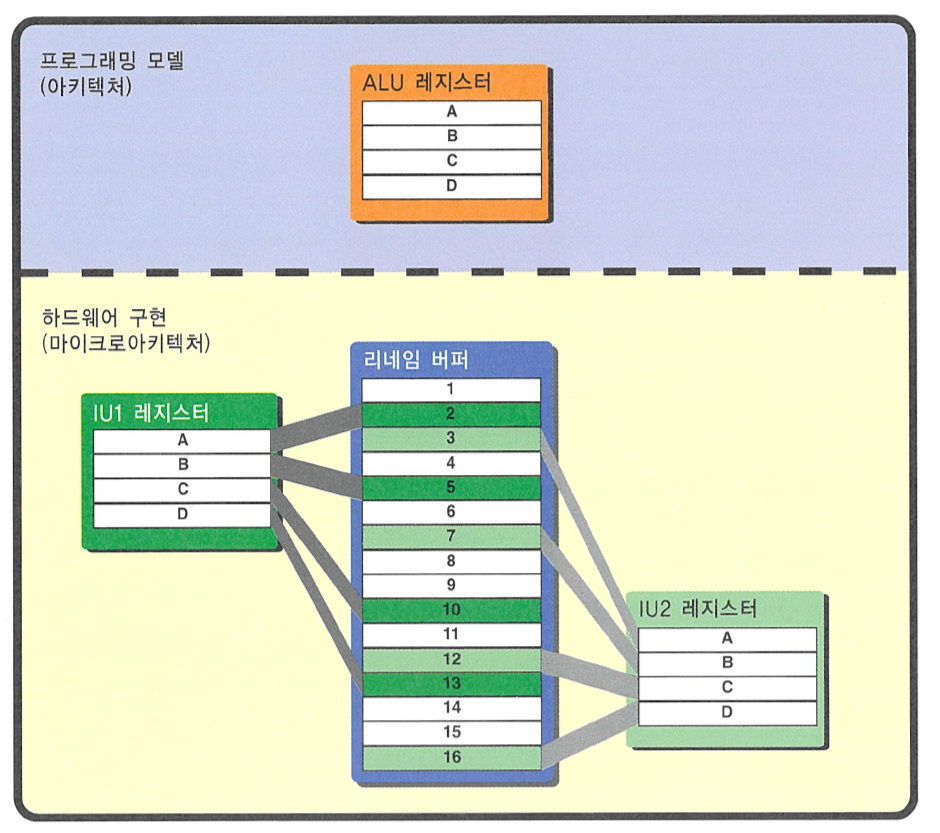 레지스터 리네임
레지스터 리네임
임시 변수를 활용한 트릭
- 아래 코드와 같이 임시 변수를 사용하여 해결이 가능하다.
/* WAR 의존성 */
C = A + B;
A = C + A;
/* Temp 변수를 이용하여 데이터 의존성 제거 */
C = A + B;
Temp = A;
A = C + Temp;
Structural Hazards - 구조 해저드
- 아래 프로그램은 데이터 의존성이 없기 때문에 병렬 수행이 가능해야 한다.
- 아래 2개 명령어를 2개 ALU 에서 동시에 수행하기 위해서는
필요한 레지스터에 동시에 접근할 수 있어야 한다.
- 아래 2개 명령어를 2개 ALU 에서 동시에 수행하기 위해서는
- 하지만 레지스터 파일이 동시에 1개의 쓰기만을 지원할 경우, 2개의 명령어를 동시에 수행할 수 없다.
- 하드웨어 자원 부족으로 발생하는 문제.
 구조 해저드 예제
구조 해저드 예제
레지스터 파일
- 여러개의 ALU 를 사용하는 수퍼스칼라 프로세서에서
각 ALU 와 레지스터를 직접 연결하기 위해서는 수많은 전선이 필요함. - ALU 에서 특정 레지스터에서 값을 읽어오려면 읽기 포트가 필요하고, 쓰려면 쓰기 포트가 필요.
- 두개의 ALU 에서 동시에 명령어를 수행하려면 4 개의 읽기 포트와 2 개의 쓰기 포트가 필요.
- 소스는 2개씩 이므로.
- 두개의 ALU 에서 동시에 명령어를 수행하려면 4 개의 읽기 포트와 2 개의 쓰기 포트가 필요.
- 레지스터가 차지하는 회로 면적은 포트 수의 제곱에 비례하므로, 포트 수에 제한이 있음.
- 오늘날 CPU 는 명령어 종류에 따라 각각 별도의 레지스터 파일을 사용하는게 보통
- 서로 다른 종류의 수행 유닛이 하나의 레지스터 파일을 사용한다면, 레지스터 파일의 크기가 너무 커지므로.
- 레지스터가 커지면 커질수록 레지스터 데이터에 접근하는 시간이 길어진다.
Control Hazards - 제어 해저드
- 분기 해저드라고도 한다.
- 분기 조건의 있으면 분기 조건을 평가하고, 분기 목적지를 계산할 때까지 파이프라인이 멈춰있어야 한다.
sub A, B, A
jumpz LBL1
add A, 15, A
LBL1 :
add A, B, B
- 위의 프로그램에서 2번째 명령 jumpz 는 1번째 명령의 결과를 알아야 결정할 수 있다.
- A == B : LBL1 으로 jump 하여 add A, B, B 를 수행.
- A != B : 순차적으로 add 15, A, A 를 수행.
- 따라서 아래와 같이 파이프라인 멈춤이 발생할 수밖에 없다.
- 또한 3ns 에서 add A, 15, A 를 수행할지 add A, B, B 를 수행할지 알 수 없다.
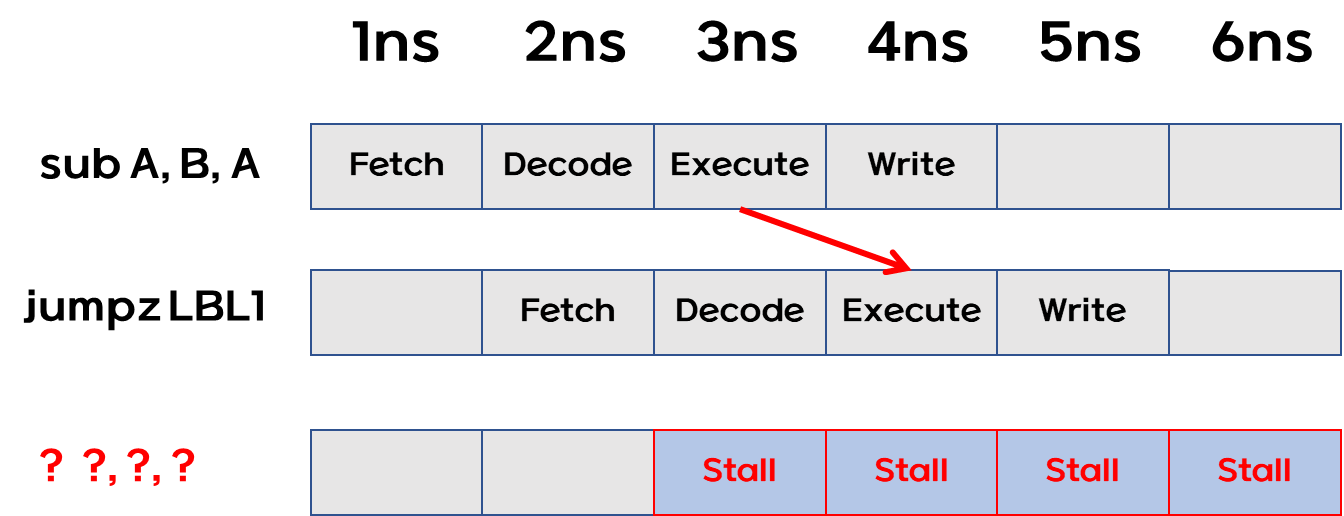 제어 해저드 예제
제어 해저드 예제
- 분기 예측을 써서 극복 가능.
- 분기예측은 캐시와 분기예측을 이용한 성능 향상] 에서.
명령어 로드 지연시간 ( instruction load latency )
- 다음 명령어의 주소를 프로그램 카운터에 쓴 후 저장소에서 명령어를 실제 페치하는 데까지 걸리는 시간.
- 어떤 저장소에 저장 되어있느냐에 따라 수사이클에서 수천 사이클까지 차이가 날 수 있다.
- 보통 캐쉬를 통해 지연시간을 단축시킨다.
다음 주제
