
[인사이드 머신] - 3. 병렬화를 통한 성능 향상 - 파이프라인
명령어의 생명 주기와 기본 흐름
2. 프로그램 실행의 원리 에서 본 fetch-execute cycle 을 더 자세히 알아보고,
이를 병렬화 하여 최적화 하는 과정을 알 수 있다.
명령어의 생명 주기
- 컴퓨터는 3 단계 수행을 반복해서 하나의 프로그램을 수행한다.
- 페치, 디코드, 수행
- 이중 수행은 다음과 같이 3 단계로 나눌 수 있는데 이중 마지막 단계인 레지스터에 쓴다는 따로 처리한다.
- 소스 레지스터의 값을 읽는다.
- 소스레지스터의 값을 연산한다.
- 결과를 목적 레지스터에 쓴다.
- 따라서 컴퓨터 수행단계는 다음과 같이 4개로 나눌 수 있다.
- fetch 페치
- decode 디코드
- execution 수행
- 소스 레지스터의 값을 읽는다.
- 소스레지스터의 값을 연산한다.
- write or write-back 쓰기
- 위의 4 스테이지는 명령어의 생명주기에서 1 Clock 을 나타낸다.
- 각각 한 스테이지 수행에는 일정한 시간이 걸린다.
- 실제로는 그렇지 않은 경우가 더 많다.
- 여기서 각 단계가 1ns 가 걸린다면 가상의 DLW-1 프로세서는 4ns 마다 하나의 명령어를 완료한다.
- 각각 한 스테이지 수행에는 일정한 시간이 걸린다.
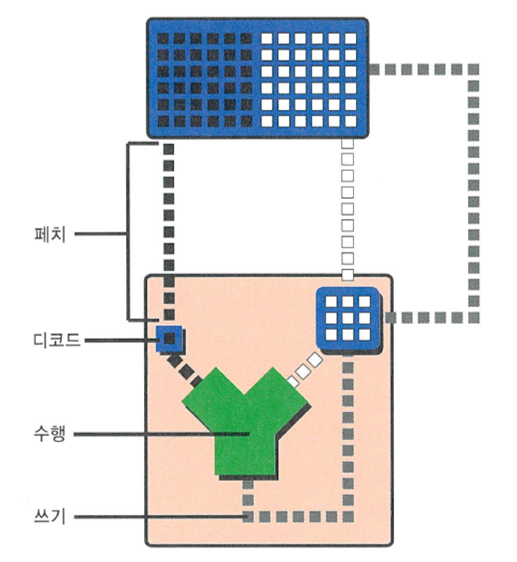 명령어 수행 4단계
명령어 수행 4단계
명령어의 기본 흐름
- Front-End 프론트엔드
- 명령어를 읽어와 해석하는 과정
- Back-End 백엔드
- 실제 연산을 한 후, 그 결과를 쓰는 과정
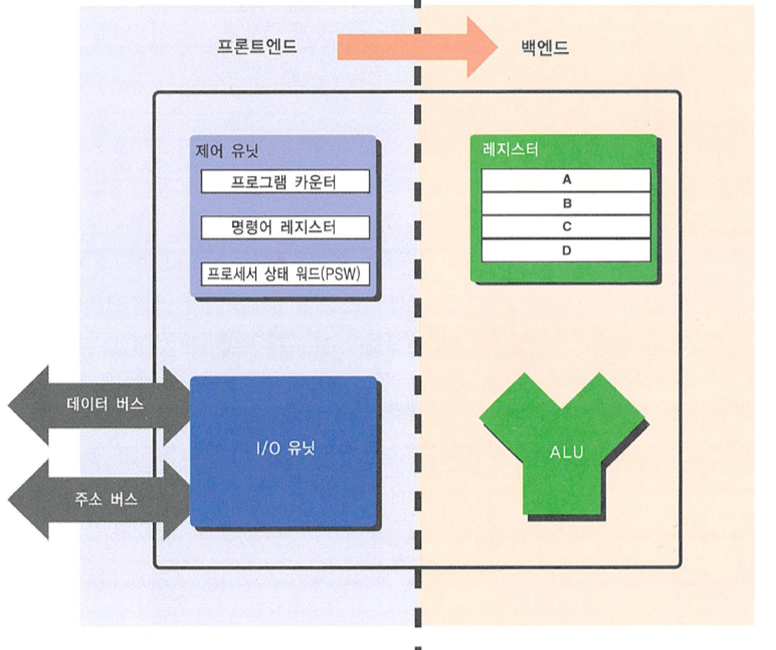 프론트엔드와 백엔드
프론트엔드와 백엔드
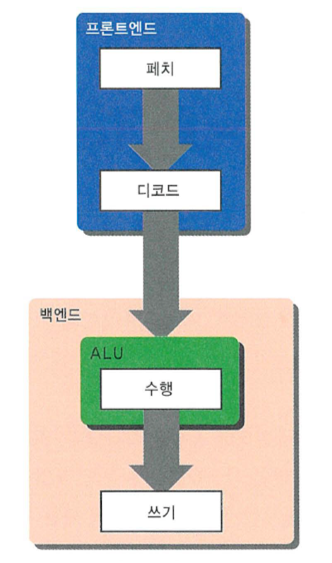 프론트엔드와 백엔드에서 명령어의 기본 흐름
프론트엔드와 백엔드에서 명령어의 기본 흐름
파이프라인
- 시스템의 효율을 높이기 위해 명령문을 수행하면서 몇 가지의 특수한 작업들을 병렬 처리하도록 설계된 하드웨어 기법.
단일 사이클 프로세서
- 하나의 명령어가 1 클럭 사이클 동안 수행 4단계를 모두 거치며 처리된다.
- 하나의 명령어를 수행하는데 정확히 1 클럭 사이클이 소요된다.
- 명령어 처리량은 클럭 속도에 정확히 비례하므로, CPU 의 클럭 사이클은 무조건 높을수록 좋다.
 단일 사이클 프로세서
단일 사이클 프로세서
- 프로세서 완료율
- 시간당 처리할 수 있는 명령어 수.
- 한 스테이지당 1ns 즉 1클럭당 4ns 가 소요될 때
- 0.25 명령어/ns ( = 1 명령어 / 4ns )
- 단순하기 때문에 설계가 쉽지만, 하드웨어 자원을 효율적으로 사용하지 못한다.
- 그림상의 흰 부분은 유용한 일을 하지 않은 채, 할일을 기다리고 있는 프로세서 하드웨어를 나타낸다.
파이프라인 프로세서
- 명령어 수행 과정(수행 4 단계)을 각각의 최적화된 하드웨어에 의해 수행되는 별도의 파이프라인 스테이지로 분리.
- 스테이지 1: 명령어를 코드 저장소에서 페치
- 스테이지 2: 명령어를 디코드
- 스테이지 3: 명령어를 수행
- 스테이지 4: 명령어 수행 결과를 레지스터 파일에 쓴다.
- 파이프라인 스테이지의 수를 파이프라인 깊이 라고도 한다.
- 각 파이프라인 스테이지는 자신의 작업을 다음 스테이지에 넘겨준 후 다음 명령어의 작업을 가져와 수행한다.
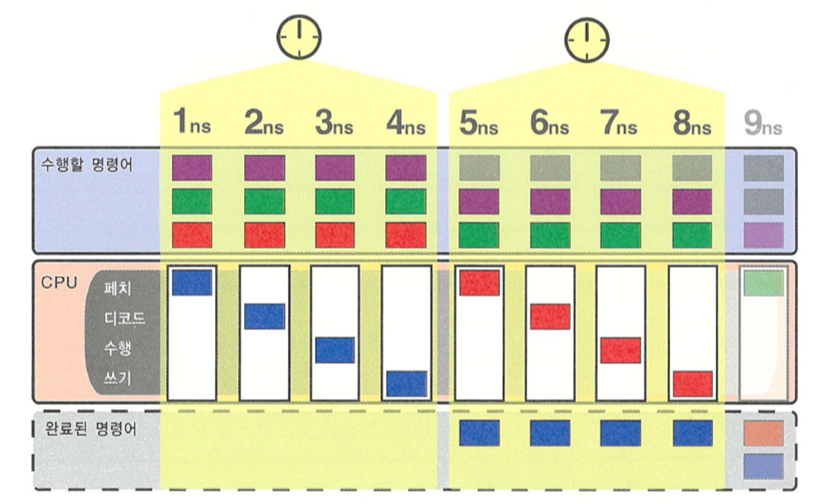
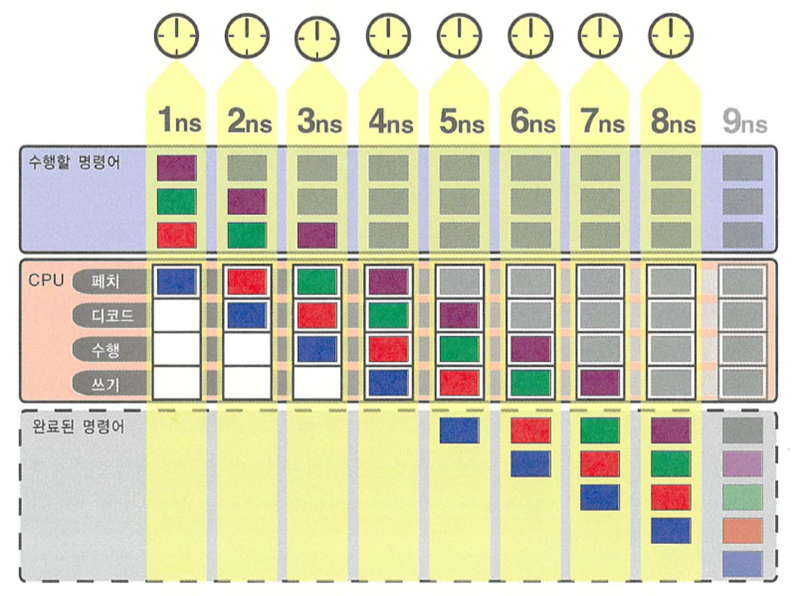 4스테이지 파이프라인
4스테이지 파이프라인
- 프로세서 완료율
- 한 스테이지당 1ns 즉 1클럭당 4ns 가 소요될 때
- 1 명령어/ns ( = 5ns 이후 시점부터 4 명령어 / 4ns )
- 한 스테이지당 1ns 즉 1클럭당 4ns 가 소요될 때
- 이론적으로 n 파이프라인의 경우 단일 사이클 프로세서보다 최대 n 배의 완료율을 보여준다.
프로그램 수행시간
- 파이프라인이 적용되더라도 각 명령어의 수행시간 자체는 바뀌지 않는다.
- 단일 프로세서나 파이프라인이나 각 명령어를 수행하는데 1 Clock 이 걸린다.
- 하지만 일정 시간 동안 수행되는 명령어의 수를 증가시켜 프로그램 수행시간을 단축할 수 있다.
- n 파이프라인은 단일 사이클 프로세서보다 최대 n 배의 완료율을 보여준다.
그런데 항상 n 파이프라인이 n 배의 성능 향상을 가져올까??
프로그램 수행시간과 완료율
- 프로그램 수행시간은 다음과 같이 나타낼 수 있다.
- 프로그램 수행시간 = 프로그램 명령어 수 / 명령어 완료율
- 프로세서의 성능에 대해 언급할 때, 그 기준은 대부분 프로그램 수행시간이다.
- 따라서 프로그램 수행시간을 단축하는 것은 프로세서 성능을 향상시키는 것을 의미.
- 단일 사이클 프로세서의 경우 명령어 완료율은 단순히 명령어 수행시간의 역이다.
- 이 때 완료율과 프로그램 수행시간의 관계는 비례이므로, 명령어 수행시간을 단축하면 된다.
- 파이프라인은 명령어 수행시간의 변화 없이 프로세서의 완료율을 변화시킬 수 있다.
- 파이프라인으로 인한 완료율 증가는 때로 1개의 명령어 수행시간을 증가시킬 수 있다.
- 따라서 파이프라인은 명령어 수행시간이 아닌 완료율이 프로세서 성능의 지표가 된다..
- 파이프라인으로 인한 완료율 증가는 때로 1개의 명령어 수행시간을 증가시킬 수 있다.
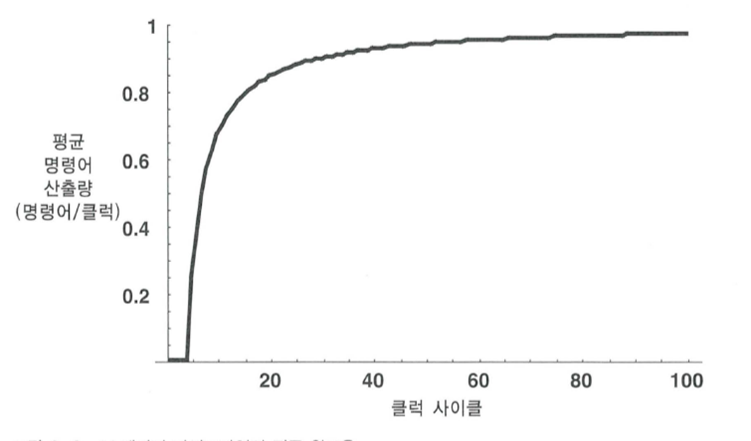 4스테이지 파이프라인의 평균 완료율
4스테이지 파이프라인의 평균 완료율
프로그램 수행시간과 완료율의 관계
- 프로세서가 첫 명령어를 끝내기 전까지(빈 파이프라인에 명령어를 채우기 시작해서 첫 명령어를 완료하는 시간까지)
완료율은 0 이 되며, 이 이후부터 완료율은 증가하기 시작한다. - 전체 프로그램 실행시간에 비해 이 첫 명령어의 종료 시간은 매우 적으므로
이론상 최대 완료율과 평균 완료율의 차이가 생긴다
명령어 산출량과 파이프라인 멈춤
- 파이프라인은 여러 가지 측면에서 프로세서를 복잡하게 만든다.
- 파이프라인 각 스테이지 동기화를 위해 마이크로프로세서의 제어 유닛이 복잡해 진다.
- 성능 측정 방법이 복잡해 진다.
instruction throughput - 명령어 산출량
- 더욱 보편적인 프로세서 성능 평가 잣대
- 명령어 산출량
- 한 클럭 사이클마다 종료되는 명령어 수
- IPC(instruction per clock) 이라고도 한다.
- 이론적 최대 명령어 산출량
- 프로세서가 한 클럭 사이클마다 수행할 수 있는 이론상 최대 명령어 수.
- 평균 명령어 산출량
- 일정 시간동안 프로세서가 실제로 달성한 IPC
- 명령어 산출량
pipeline stall - 파이프라인 멈춤, 파이프라인 버블
- 프로세서 동작 중에 하나의 명령어가 같은 스테이지에서 몇 클럭 동안 머무르는 일
- 파이프라인 멈춤이 일어난 스테이지 이후에 있는 스테이지의 명령어는
정상적으로 수행되지만 이전의 명령어 수행은 모두 멈춘다.- 이로 인해 멈춘 기간 만큼 앞 명령어와의 사이에 간격이 생기고,
멈췄던 명령어가 재개될 때 다음 스테이지로 넘어갈 때 함께 넘어간다. - 이 간격을 파이프라인 버블 이라고도 한다.
- 파이프라인 버블은 파이프라인 병렬화 - 수퍼스칼랑 수행 에서 자세히 다룬다.
- 이로 인해 멈춘 기간 만큼 앞 명령어와의 사이에 간격이 생기고,
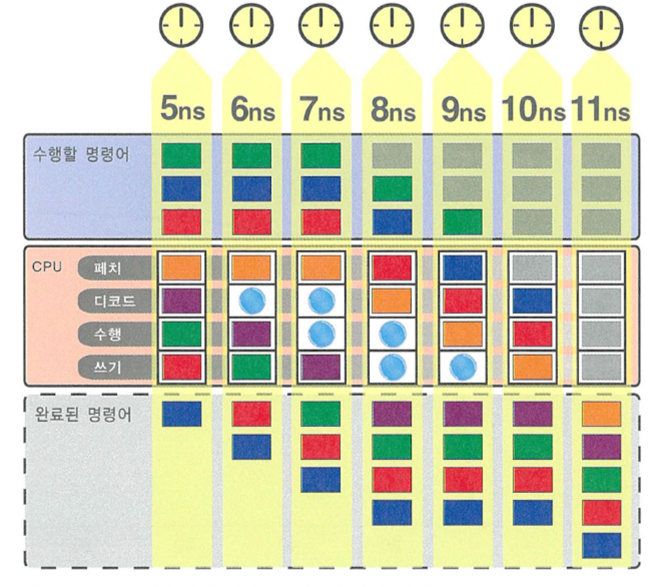 4 스테이지 파이프라인 프로세서에 파이프라인 멈춤으로 인해 버블이 생긴 모습
4 스테이지 파이프라인 프로세서에 파이프라인 멈춤으로 인해 버블이 생긴 모습
- 파이프라인 멈춤은 평균 명령어 산출량을 감소시킨다.
- 실제 프로그램에서 수많은 명령어가 파이프라인 멈춤을 야기하고,
이에 따라 상당한 성능 저하를 초래할 수 있다.
- 실제 프로그램에서 수많은 명령어가 파이프라인 멈춤을 야기하고,
- 파이프라인 멈춤은 프로세서 설계자에게 있어 매우 중요한 문제.
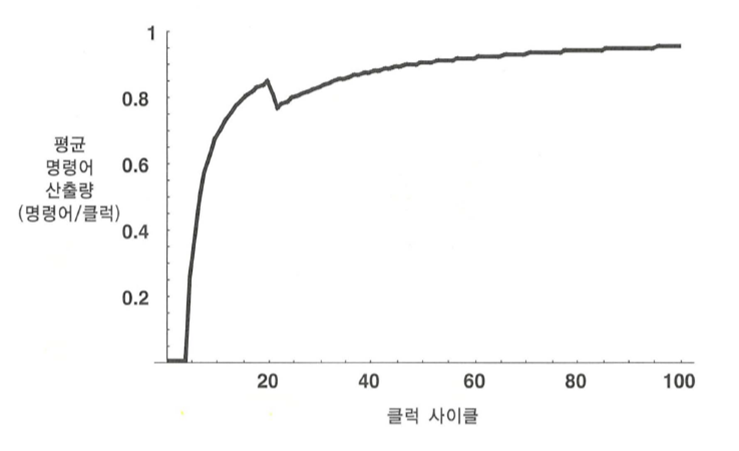 4 스테이지 파이프라인 프로세서에 2 클럭 동안 파이프라인 멈춤이 발생했을 때의 평균 명령어 산출량
4 스테이지 파이프라인 프로세서에 2 클럭 동안 파이프라인 멈춤이 발생했을 때의 평균 명령어 산출량
pipeline flush - 파이프라인 비움
- 분기 예측등으로 파이프라인을 미리 채워놨으나, 분기 예측이 실패하여 미리 채운 파이프라인을 모두 비우는 현상.
- 분기 예측은 캐시와 분기예측을 이용한 성능 향상 에서.
sub A, B, C
jumpz LBL1
add A, 15, A
LBL1 :
add A, B, B
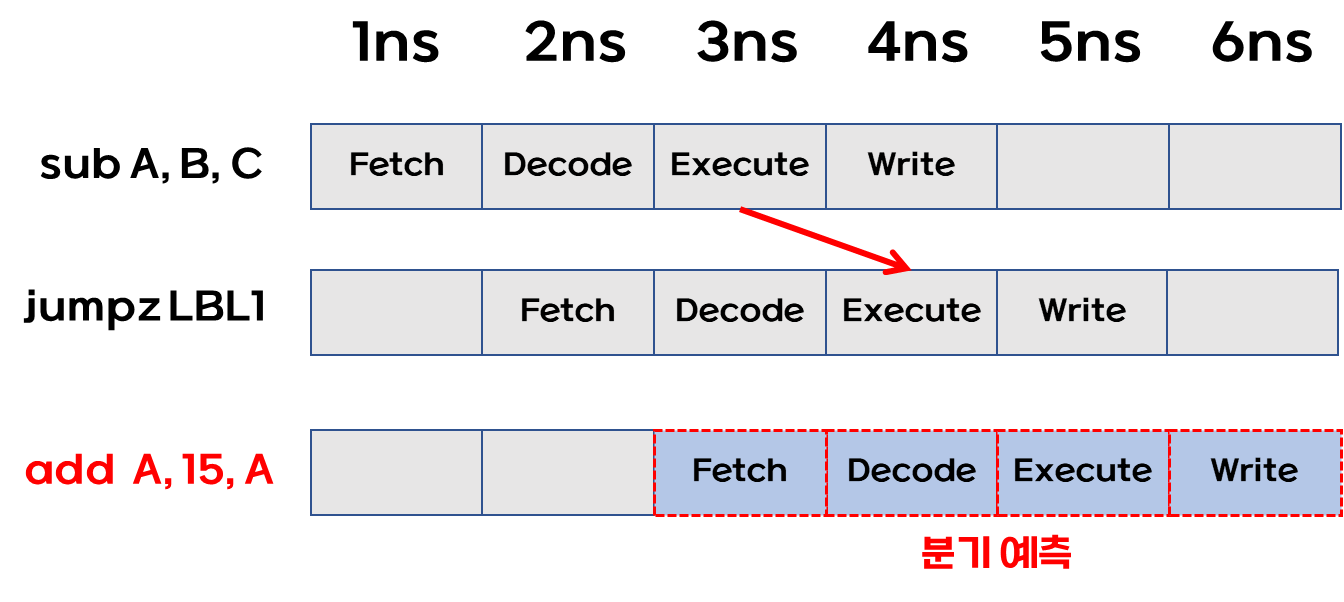 분기 예측으로 파이프라인을 미리 채움
분기 예측으로 파이프라인을 미리 채움
- 위의 프로그램에서 2번째 명령 jumpz 는 1번째 명령의 결과를 알아야 결정할 수 있다.
- A == B : LBL1 으로 jump 하여 add A, B, B 를 수행.
- A != B : 순차적으로 add 15, A, A 를 수행.
- 분기 예측이 A == B 를 예측하고 이를 미리 채운다.
- 하지만 분기 예측이 실패할 경우 미리 채운 파이프라인을 비워야 한다.
- 실제 분기 예측은 아래와 같이 하나만 채우지 않고 많은 양을 한꺼번에 채우기 때문에
이로 인해 비용이 상당히 클 수 있다.
- 실제 분기 예측은 아래와 같이 하나만 채우지 않고 많은 양을 한꺼번에 채우기 때문에
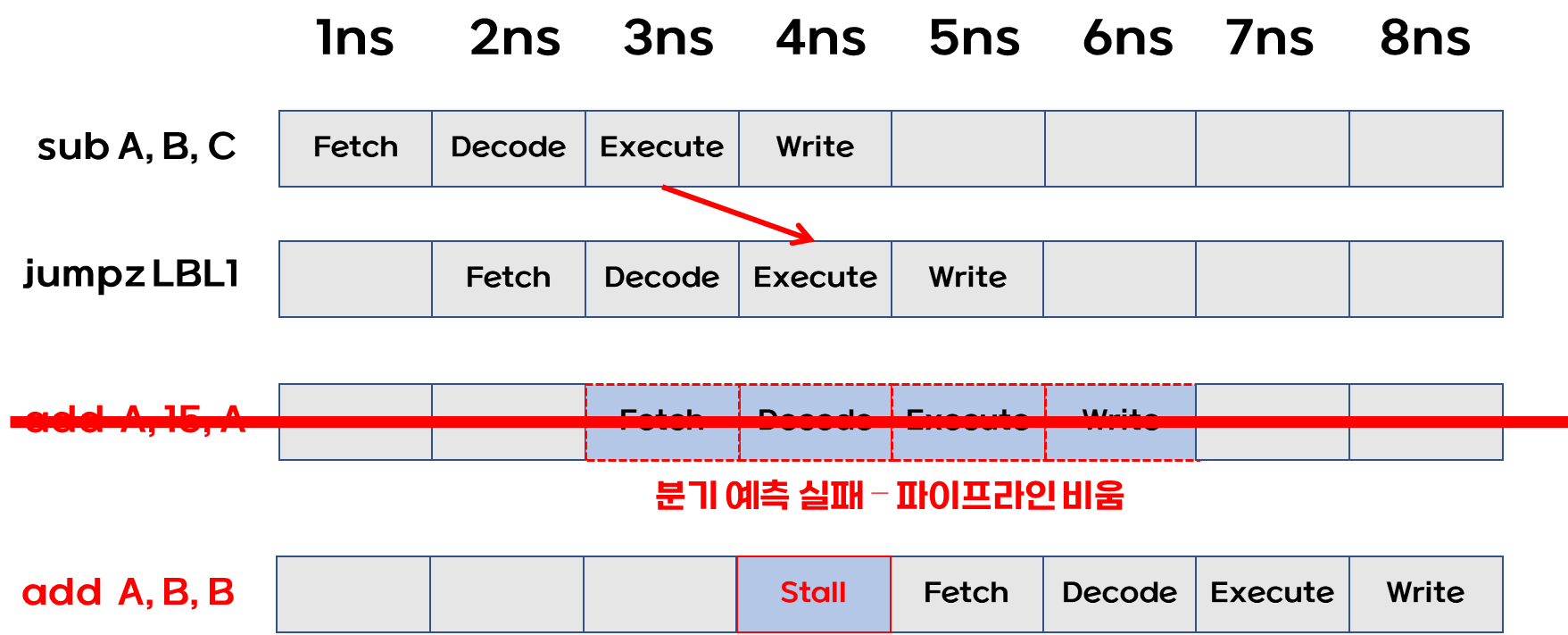 분기 예측실패로 파이프라인 비움
분기 예측실패로 파이프라인 비움
파이프라인의 한계
- 파이프라인으로 인한 이득이 이상적인 경우보다 훨씬 떨어지게 된다.
- 명령어의 생명 주기가 완전히 균일한 여러개의 스테이지로 나눠지지 않는다.
- 각 파이프라인 스테이지는 모두 1 클럭 사이클 안에 수행되야 하므로
가장 느린 스테이지가 CPU 의 클럭 사이클을 결정한다.- 가장 느린 스테이지는 1 싸이클을 전부 사용하지만,
빠른 스테이지는 사이클의 일부를 아무것도 하지 않은 채 느린 스테이지를 기다리게 된다. - 따라서 산출량을 높이기 위해 파이프라인 스테이지를 추가하다 보면,
스테이지 간 수행시간의 편차가 점점 커지고,
그에 따라 프로세서의 평균 명령어 수행시간이 길어진다.
- 가장 느린 스테이지는 1 싸이클을 전부 사용하지만,
- 각 파이프라인 스테이지는 모두 1 클럭 사이클 안에 수행되야 하므로
- 파이프라인 스테이지가 많아질수록 파이프라인을 모두 채우는데 더 많은 시간이 걸리는 것을 의미한다.
- 즉 완료율이 완만하게 올라간다.
- 프로그램을 수행하다 보면 기존 파이프라인의 내용을 버리고(flush),
코드 스트림의 다른 부분부터 파이프라인을 새로 채워야 할 경우가 많기 때문에,
완료율이 완만하게 올라갈 경우 프로세서 성능에 악영향을 미칠 수 있다.
- 명령어의 생명 주기가 완전히 균일한 여러개의 스테이지로 나눠지지 않는다.
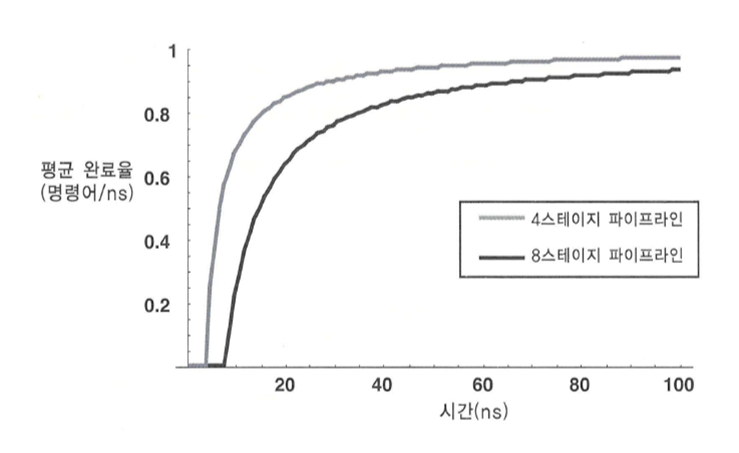 1ns 클럭으로 동작하는 4 스테이지 및 8 스테이지 프로세서의 완료율 변화
1ns 클럭으로 동작하는 4 스테이지 및 8 스테이지 프로세서의 완료율 변화
파이프라인 성능 극대화를 위한 고려사항
- 파이프라인 멈춤을 최소화 시켜야 한다.
- 파이프라인 비움을 피해야 한다.
- 파이프라인을 비우고 다시 채우는 것은 완료율과 성능 모두에 심각한 악영향을 끼친다.
파이프라인의 비용
- 파이프라인을 통한 성능 향상에는 한계가 있다.
- 파이프라인은 추가 버퍼 회로가 필요하여 비용 문제가 발생.
- 더 많은 트랜지스터를 필요하므로 프로세서의 크기가 커진다.
- 프로세서를 설계할 때에는 성능 향상과 비용 문제를 함께 고려해서 현실적인 파이프라인 깊이를 정해야 한다.
다음 주제
[인사이드 머신] 파이프라인 병렬화 - 수퍼스칼랑 수행
